
What is Cloud Computing?
24 Jun , 2021
The “cloud” is just computers–lots and lots of them, stacked up in warehouses around the world. The companies that run these computers lease them out to organizations, who pay for the resources they use up. Pretty simple.
So why do people make such a big deal out of the cloud?
Because they remember how much worse off they were before it.
The Problem with Traditional IT
Cloud computing is popular for the same reason a carton of eggs only costs a few dollars.
Back in the day, if you wanted eggs, you needed chickens: at least two–a rooster and a hen, to do the dirty with each other–and ideally many more, to produce the quantity of eggs you’d need to feed your family. Those chickens would need to be housed somewhere, of course, and given their own food and other care. A lot of work.
Today we have poultry farmers and corporations that go to remarkable, even inhumane lengths to produce eggs for everyone. In raising thousands of chickens at a time, the cost of producing any single egg is rather miniscule, thus they can be sold at low prices to you.
We call poultry farms–and clothing manufacturers, Spotify, Amazon Prime and the banking system–economies of scale. In economies of scale, large enterprises spread fixed costs–like expensive machinery, maintenance, administration and so on–across more units of production, allowing for a lower cost per individual unit. So where producing a single egg is a lot of work for you, it’s nothing to a poultry farmer.
To support sophisticated IT, businesses can (and used to have to) operate their own chicken coops. CIOs and their teams created their own mini data centers on their own premises (“on prem”), cordoning off entire rooms full of servers and wires.
There is an upside to DIY IT: it allows for granular control over every aspect of the architecture and design of a system. A government agency that values security very highly might spend more on the equipment and software necessary to keep intruders out, while a company that doesn’t have to worry about such things might focus on efficiency.
But doing A to Z on prem is expensive and inefficient, like running your own chicken farm just to have eggs in the morning. It requires lots of time and effort from lots of employees, and significant, upfront investment in equipment. At the same time, a company’s needs are constantly changing, and the infrastructure will have to change to reflect that. Any equipment is going to age, too, which introduces maintenance and repair and replacement costs. The headaches go on and on.
Wouldn’t it be so much easier to just buy some eggs from a farmer?
An Idea for a New Approach
One company that understood well the complexities of having to run an enterprise IT network was Amazon. To support their online shopping business, they needed all kinds of large-scale but efficient systems.
A former Amazon network manager, Benjamin Black, recalled what it was like to be handling the levers running the world’s biggest shopping site in a 2009 blog post:
[My manager] was always pushing me to change the infrastructure, especially driving better abstraction and uniformity, essential for efficiently scaling. He wanted an all IP network instead of the mess of VLANs Amazon had at the time, so we designed it, built it, and worked with developers so their applications would work with it. He wanted anycast DNS, so we hacked up some routing software and put it out there[.]
In late 2003, Black and his manager, Chris Pinkham, began developing a new idea–not so much an improvement, but a sea change. “It struck us in the infrastructure engineering organisation,” Pinkham recalled to ZDNet, “that we really needed to decentralise the infrastructure by providing services to development teams.”
Chris and I wrote a short paper describing a vision for Amazon infrastructure that was completely standardized, completely automated, and relied extensively on web services for things like storage. We drew on the work of a number of other folks internally who had been thinking and writing (and sometimes even coding) in the storage services space, and we combined it with our own thinking and experience in infrastructure.
Really it was, in Jeff Bezos’ own words, “11 years of web-scale computing [and] multiple billions of dollars in technology and content investment,” all coming together.
But the real kicker came at the end of the proposal:
Near the end of it, we mentioned the possibility of selling virtual servers as a service.
It was a novel concept: running servers not just for Amazon’s own purposes, but to sell to other companies.
Black and Pinkham presented their paper to Bezos, who liked it. A few months later, in 2004, the idea started to get its legs–Black and Pinkham wrote up more detailed plans, the company produced a press release with an FAQ, and began to put together a team.
Except it wasn’t all easy.
Recall what we said earlier: building data infrastructure from the ground up is expensive and inefficient, but it also gives IT teams immense control. Pinkham and Black’s idea–an infrastructure service that operated remotely and for anyone–required some of that control to be relinquished. In 2010, a technology blogger asked Amazon’s former “Master of Disaster,” Jesse Robbins, what it was like:
I was horrified at the thought of the dirty, public Internet touching MY beautiful operations,” he said with all the relish of a born operator. Robbins had his hands on the reins of the world’s most successful online retail operation from soup to nuts and wasn’t about to let it be mucked up with long-distance experimentation.
The project might have encountered further resistance, but for one rather random factor. Chris Pinkham, the project lead, had a pregnant wife, and wanted to move the family back to his home country of South Africa. Rather than lose him, Amazon allowed the entire project to move into a satellite office in Cape Town. Incidentally, that distance gave the project a degree of creative freedom. “It might never have happened,” Robbins recalled, “if they weren’t so far away from the mothership.”
By the following year, Amazon was secretly providing its new distributed computing service to select clients. In 2006, “Elastic Compute Cloud” (EC2), the “infrastructure service for the world,” officially launched.
Benefits of Cloud Computing
It took a little while for cloud computing to catch on. Perhaps some of that had to do with how novel the idea was. Perhaps there were other Jesse Robbins’ out there–folks who, understandably, didn’t want to give up the unanimous control they had over their systems.
Eventually, though, cloud blossomed into the hundred-billion-dollar industry it is today. And it got there the old fashioned way: by offering an undeniable value proposition.
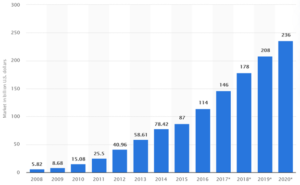
(image captured from Statista)
Let’s consider some of the reasons why any organization might want to move to the cloud:
1. Long-Term Scaling
Investing in IT, for a growing business, is like investing in clothing for a child. There’s no winning. You can buy what fits now but, inevitably, it’ll be too small later. You can buy a size or two up, but you won’t need it for a while, or if you try to fit it on now it’ll be all out of proportion. What ends up happening, ultimately, is that you buy and buy and buy more every year or so.
In the cloud, everybody shares a pool of servers that, when managed properly, always have extra room left over. And because those servers are rented rather than purchased by clients, they’re never used any more or less than they’re needed. So a business that doubles in size in a single year might end up spending twice as much on the cloud, but they’ll never run out, or be left with too much. The size always fits perfectly.
2. Short-Term Scalability
Say you own a Halloween store. How much IT infrastructure do you invest in, to keep your web store running?
It’s tricky. You can try to save on costs, but when October rolls around it’ll probably crash your site. You can invest in enough capacity to handle October traffic, but ten months out of the year it’ll be collecting dust.
On-demand computing eliminates this problem entirely. Your store will pay low rates November through August, and higher rates–in exchange for uncompromised performance–during September and October. Cloud providers straddle the traffic with ease, because one Halloween store leaves a miniscule imprint compared with all the other businesses running over the same cloud infrastructure.
If there’s ever a time when cloud providers really can’t keep up, it’s when large numbers of businesses all experience peak traffic at once. A good example of this is Black Fridays. It’s not uncommon for online retailers to experience even ten times their ordinary traffic on Black Friday weekends. Now take that and multiply it across all the online retailers using the cloud at the same time. It gets crowded.
Black Friday 2020 may have been the single most taxing period in the history of the cloud. With COVID-19 social distancing in place, consumers were relying on online stores more than ever. And, to compound the problem, one of Amazon’s biggest data centers–US-East-1–went down at around 9:00 AM EST on Wednesday the 25th.
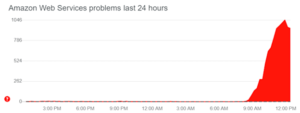
(image via DownDetector)
Fortunately the problem was largely resolved by 10:30 PM EST, just in time for the holiday, and such organizations as Adobe, Roku and the MTA were able to resume normal operation.
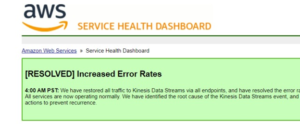
(image via Engadget)
3. Resiliency
The US-East-1 incident demonstrated how an issue at a single data center can spell trouble for hundreds of companies at a time. This is a risk unique to the cloud.
On the flip side, the cloud makes it possible to spread risk and increase resiliency. Think about it: if a company hosts all their own IT infrastructure, and a critical machine goes down, there’s nowhere else to turn. The whole system fails. By running data centers at multiple locations, cloud providers don’t have this problem–they can host a client’s data at multiple locations worldwide, or move data from one location to another. Perhaps it’s not so meaningful when you’re counting in hours, like the US-East-1 outage, but in general it allows for any potential issues in one location to be supported by free machines elsewhere.
4. Security
Possibly the greatest psychological barrier to cloud adoption comes with relinquishing control over security. Your most sensitive data might be sitting on servers thousands of miles away, being controlled by people you don’t know. It requires a degree of trust.
Cloud providers understand that. More importantly, they understand that, were a breach to occur, they themselves would lose billions of dollars overnight.
That’s why data centers operate with not only the highest-grade cybersecurity, but also the kind of physical security you really only see in spy movies. We’re talking barricaded perimeters, guards (sometimes armed), cameras everywhere, layers and layers of security gates, laser-activated alarms, the works.
You’re better off hacking the Pentagon, or breaking into the U.S. Capitol, than messing with a cloud data center.
5. Cost
In the cloud, computing is an operational expense, not a capital one. Continuous, not fixed. Instead of the upfront costs of purchasing machinery, clients pay the monthly costs associated with how much computing resource they use from the provider. From a cost standpoint, there are multiple benefits to this system.
On a micro level, clients don’t have to worry about paying for more than they’ll use–on a yearly, daily or even minute-by-minute timescale, as is the case with on prem IT.
At the macro level, cloud providers achieve an economy of scale that greatly reduces price per unit of computing. They house huge numbers of servers in what seem like massive spaces, but are in fact, per capita, relatively condensed. Compared to how many employees it’d take to run on prem data infrastructure at individual companies worldwide, the staff at a data center is basically a skeleton crew. Apply that same logic to cybersecurity, HVAC, and so on, and you start to get the picture: data centers are highly efficient. That efficiency is then passed onto customers.
The Bottom Line
The cloud certainly isn’t without its faults. Cloud takes some degree of control out of the hands of CIOs, and demands trust of CISOs–a risky proposition. They’re big, fat targets for hackers. It can be tricky to switch providers if you’re unhappy. All of the cloud is online, which becomes a problem when internet connectivity falters. And one failure can create a giant regional impact, as we saw with US-East-1, or the infamous typo that cost businesses hundreds of millions of dollars one morning in 2017.
Overall, though, the economy of scale that cloud computing provides leads to increased performance, efficiency and cost savings that are too great for most organizations to pass up. And in addition to everything already mentioned, there are all kinds of benefits we haven’t fit in this article: loss prevention, disaster recovery, increased mobility and collaboration, automatic software updates, and so on.
So, now you know what the cloud is–a bunch of computers, stacked up in warehouses, that people rent on-demand–and why it’s so popular.
But there’s one thing you still don’t know. It’s the greatest mystery of the cloud. Why is it called “the cloud” in the first place?
Well, for one thing, it’s a nice marketing term. And many sources, like CNBC, will tell you how “The phrase originates from the cloud symbol used by flow charts and diagrams to symbolize the Internet.” But this hardly explains how a cloud came to be the symbol of the internet in the first place.
That origin story dates back to early engineering diagrams. As recounted in The Atlantic:
[T]he term “cloud” dates back to early network design, when engineers would map out all the various components of their networks, but then loosely sketch the unknown networks (like the Internet) theirs was hooked into. What does a rough blob of undefined nodes look like? A cloud. And, helpfully, clouds are something that take little skill to draw.
According to some accounts, it wasn’t just convenience and poor artistry that motivated engineers to draw poorly:
[T]elecom sales engineers [. . .] despaired at ever explaining the complexities of long-distance wide-area-networking to customers (or just didn’t want to bother). In conceptual diagrams metaphorically describing how a prospective customer’s facilities could all be connected to the same network (a revolutionary idea in the ’70s and early ’80s), they included images of the customer’s buildings with specific references to the type of leased-line connecting each to the carrier’s network. Rather giving away too much information on their own infrastructure (or confusing customers) by describing the telco’s own internal networking infrastructure, they drew a fluffy cloud, surrounded by the customer’s facilities. In diagrams customer data would flow across expensive leased lines from one facility, enter the magic telco cloud, and come out on the other end to flow into another company facility through another expensive leased line.
It’s a “cloud” because the actual technology is just too complicated for most people to grasp.
So, if it took you until today to figure it out, you’re in good company. This stuff is confusing. Easier just to picture a nice cloud.
